This is part 2 of our 8 SEO Gifts for Chanukah series breaking down some basics of Search Engine Optimization.
What is a URL really?
Its 2 AM in the morning – I know I should be sleeping, but I found this really bizarre article about the top ten craziest conspiracy theories and I just can’t put the iPad down! I finish reading the article and decide to quickly check my emails. I type into my browser www.gmail.com and hit the return key. Suddenly I have the most random thought – “what is really going on when I type in the URL? How does my browser know where to find this website?” (It’s funny how your brain works when you are overtired). I knew I had to satisfy this curiosity before going to bed – so off to Google to find myself an answer. This is what I discovered….
URLs – Break it down now
So the first step is to figure out what is going on by breaking down the URL into components and see what each part does. Let’s take an example URL and break it down…

A. Protocol
This defines the type of communication that is to be established between the browser and the webserver where the website sits. The most common is hyper-text-transfer-protocol (http) used to receive the vast majority of websites. Also common is a secure version of http knows as https which transmits data between servers in an encrypted format.
B. Subdomain
A subdomain may be used to logically divide a website into high-level categories. For example a company that has activities in many countries may choose to add subdomains in the format us.company.com, fr.company.com, uk.company.com etc. Each subdomain will direct the user to a specific website defined by the webserver.
C. Root Domain
This is the main identifier of the site.
D. Top-Level-Domain (TLD)
Most countries offer specific TLDs (such as .co.uk or .com.au) and can be used by companies/individuals to identify a specific market that they operate in. There are also generic TLDs (such as .com or .info) that are not location specific.
E. Subfolder / Category-Request
This can either represent a physical folder on a webserver where the webpages are stored or it can simply be a request to the webserver to provide a specific category or type of page.
F. File / Page-Request
This may represent a physical file on a webserver (such as an html webpage or an image) or it could be a request to the webserver to provide a specific type of page.
G. Parameters
A website may choose to pass some parameters to the webserver. These could be used to request that the webpage is displayed in a particular way or to capture information about a user’s actions.
Hops – What happens when I hit the return key
So now that we understand what the URL components are – what actually happens when I hit the return key? Well, quite a lot happens – and all in milliseconds!! Multiple steps occur, known as hops to get you the website you requested. We will analyse a few of the key ones below…
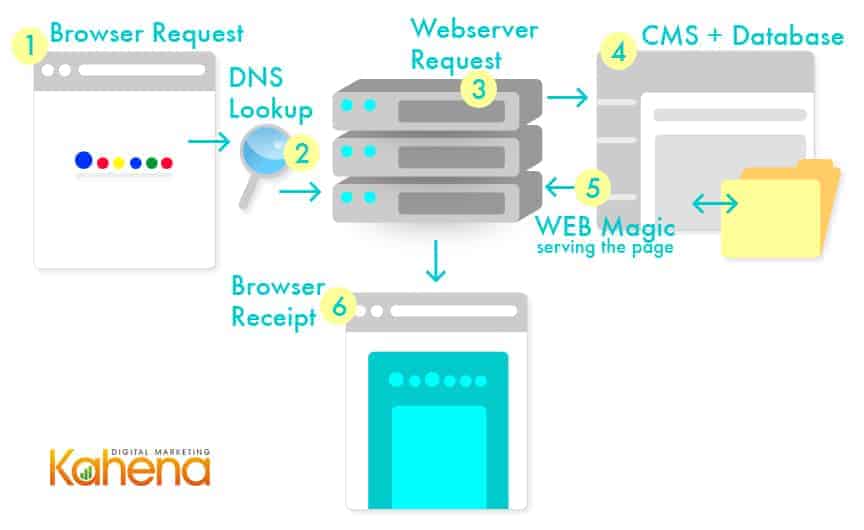
1. Browser Request
First step – your internet browser prepares a request for information and sends it to a DNS Server (see above) via the protocol that you have entered in the URL. The request includes all the details in the URL including the domain details and the parameters.
2. Domain-Name-Server (DNS) Lookup
The DNS Server is essentially a collection of directories for (almost) all the domain names on the internet. You can think of it like a massive digital phone book. The DNS Server receives the request from the browser, looks up the domain and returns a string of numbers known as an Internet-Protocol (IP) address. The address usually is in the format XXX.XXX.XXX.XXX and is the way a specific webserver is identified, similar to the way a phone number identifies a specific mobile or landline.
3. Webserver Request
The next hop is to send the information request to the webserver (now that we know its address). The webserver will have a series of rules that will potentially accept/reject a request or redirect it to another server. Once accepted – the information request is forwarded to a Content Management System (see next step)
4. Content Management System (CMS)
A CMS is an application (or collection of applications) that control how a website is presented back to the browser. The CMS will read the URL presented by the browser and will interpret what that means in terms of the page data to be returned. Once the CMS has figured out what it is that the browser wants – it will generate a series of text strings that contain mark-up code (a special format understood by web browsers).
5. Web Magic – Serving the Page
Now the magic happens – the mark-up text strings are given by the CMS to the Webserver that in turn sends it back to the browser.
6. Browser Receipt
The browser receives the text strings and then processes them line by line. It uses these strings as instructions on how to build the page. And voila! – a web page is shown in your browser.
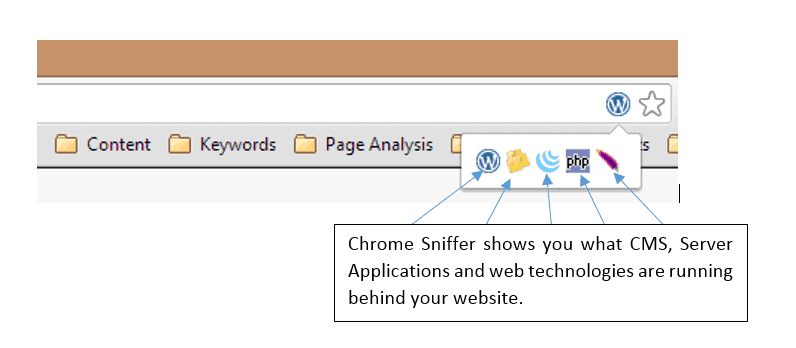
Sniff out those Site Specifics
The Chrome Sniffer Chrome Extension is great for sniffing out the framework/CMS the site is running on as well as any server applications. If you’re a site developer this is an invaluable tool to have in your arsenal.
So there you have it – the beginner’s guide to how URLs work! Quite amazing really to think that this all happens in less than a second! Now I can finally go to sleep…